There is a nice website screenshots.com that hosts historic screenshots for many websites. This post will show how to generate our own historic screenshots with python.
Source code is available on bitbucket. The script depends on python 2.5+, pyqt, and the webscraping package. For Debian based distributions this will do it:
$ sudo apt-get install python-qt4
$ sudo pip install webscrapingThe source of historic webpages will be the Wayback Machine, which has been caching webpages since 1996. I found that a new beta version is being tested, available here. Unfortunately the default version does not include any new caches since mid 2011 so this script will need to depend on the beta.
The Wayback Machine has a convenient URL structure based on timestamp:
http://web-beta.archive.org/web/YYYYMMDDHHMMSS/website
http://web-beta.archive.org/web/20121030031942/http://www.amazon.com/
http://web-beta.archive.org/web/20121123023424/http://www.amazon.com/
If just a partial timestamp is sent then the server will redirect to the nearest match. For example 2011 redirects to December 31, 2011:
http://web-beta.archive.org/web/2011/http://www.amazon.com/
->
http://web-beta.archive.org/web/20111231235154/http://www.amazon.com/
The first step is finding how far back the history is available for a webpage. At the top of the cached page for amazon.com is the message: http://amazon.com has been crawled 10,271 times going all the way back to December 12, 1998.
The link here contains a timestamp for the earliest date, which will be parsed into a datetime object:
def get_earliest_crawl(html):
# extract the URL from HTML
earliest_crawl_url = xpath.get(html, '//div[@id="wbMeta"]/p/a[2]/@href')
# extract the timestamp from the URL
timestamp = earliest_crawl_url.split('/')[2]
# parse the timestamp in to a python datetime
return datetime.datetime.strptime(timestamp, '%Y%m%d%H%M%S')Next need to iterate from this earliest timestamp to the present and download each of the cached pages in-between. The below snippet uses increments of a year between each timestamp download:
def historical_screenshots(website):
# the earliest archived time
t0 = get_earliest_crawl(website)
# the current time
t1 = datetime.datetime.now()
# get screenshots for each year
delta = datetime.timedelta(days=365)
while t0 <= t1:
timestamp = t0.strftime('%Y%m%d')
# download the cached page at this timestamp
url = 'http://web-beta.archive.org/web/%s/%s/' % (timestamp, website)
html = D.get(url)
ts += deltaWebkit is then used to generate the screenshot of each downloaded webpage. To make the results prettier the Wayback toolbar is removed before rendering:
wb = webkit.WebkitBrowser(gui=True, enable_plugins=True, load_images=True)
# remove wayback toolbar
html = re.compile('<!-- BEGIN WAYBACK TOOLBAR INSERT -->.*?<!-- END WAYBACK TOOLBAR INSERT -->', re.DOTALL).sub('', html)
html = re.compile('<!--\s+FILE ARCHIVED ON.*?-->', re.DOTALL).sub('', html)
html = re.sub('http://web\.archive\.org/web/\d+/', '', html)
wb.get(url, html)
wb.screenshot(screenshot_filename)This script includes a feature to generate a webpage with the screenshots. Here is an example history from Yahoo (follow the image link to view the complete history):
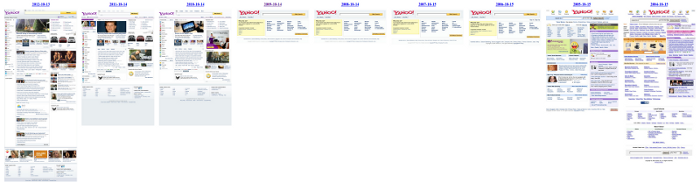
This is interesting - from 1996 to 2004 the Yahoo homepage became progressively more complex, then 2006 - 2009 drastically simpler, and then 2010 onwards returns to the traditional portal site. They must have been trying to compete with Google’s simple approach but that didn’t work so went back to being a media company.
Here are some more screenshot histories for Apple, Amazon, and IMDB.
These are among the better results I have generated so far. Often I found the Wayback Machine crawler was blocked or returned tacky domain squatter websites. If you find a website with an interesting history let me know.