Some websites require passing a CAPTCHA to access their content. As I have written before these can be parsed using the deathbycaptcha API, however for large websites with many CAPTCHA’s this becomes prohibitively expensive. For example solving 1 million CAPTCHA’s with this API would cost $1390.
Fortunately many CAPTCHA’s are weak and can be solved by cleaning the image and using simple OCR. Here are some example CAPTCHA images from a recent website I worked with:
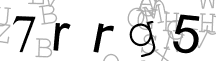 |
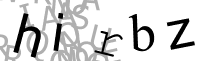 |
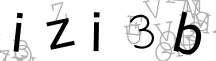 |
Helpfully the distracting marks are lighter so the image can be thresholded to isolate the text:
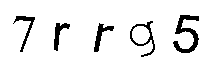 |
 |
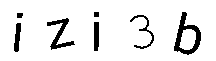 |
Now the resulting images can be passed to an OCR program to extract the text. Here are results from 3 popular open source OCR tools:
| Captcha 1 | Captcha 2 | Captcha 3 | Result | |
|---|---|---|---|---|
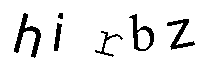
| 7rrg5 | hirbZ | izi3b | ||
| Tesseract | 7rrq5 | hirbZ | izi3b | 2 / 3 |
| Gocr | 7rr95 | _i_bz | izi3b | 1 / 3 |
| Ocrad | 7rrgS | hi_bL | iLi3b | 0 / 3 |
Excellent results. Getting 100% accuracy is not necessary when solving CAPTCHA’s, because real people make mistakes too so websites will just respond with another CAPTCHA to solve.
Tesseract only confused ‘g’ with ‘q’ and Gorc thought that ‘g’ was a ‘9’, which is understandable. Even though Ocrad did not get any correct on this small sample set, it was close every time. And this was without training on the font or fixing the text orientation.
If you are interested the Python code used is available for download here. It depends on the PIL for image processing and each of the OCR tools.