I have received some inquiries about using webkit for web scraping, so here is an example using the webscraping module:
from webscraping import webkit
w = webkit.WebkitBrowser(gui=True)
# load webpage
w.get('http://duckduckgo.com')
# fill search textbox
w.fill('input[id=search_form_input_homepage]', 'sitescraper')
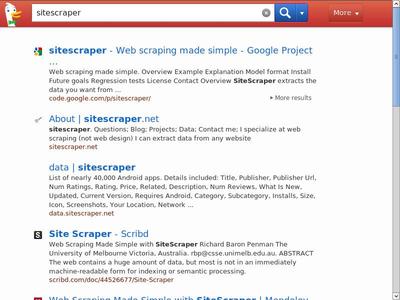
# take screenshot of browser
w.screenshot('duckduckgo_search.jpg')
# click search button
w.click('input[id=search_button_homepage]')
# wait on results page
w.wait(10)
# take another screenshot
w.screenshot('duckduckgo_results.jpg')Here are the screenshots saved:

I often use webkit when working with websites that rely heavily on JavaScript.
Source code is available on bitbucket.