Occasionally I come across a website that blocks your IP after only a few requests. If the website contains a lot of data then downloading it quickly would take an expensive amount of proxies.
Fortunately there is an alternative - Google.
If a website doesn’t exist in Google’s search results then for most people it doesn’t exist at all. Websites want visitors so will usually be happy for Google to crawl their content. This meansGoogle has likely already downloaded all the web pages we want. And after downloading Google makes much of the content available through their cache.
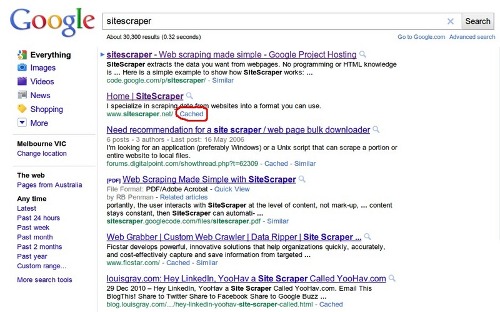
So instead of downloading a URL we want directly we can download it indirectly via http://www.google.com/search?&q=cache%3Ahttp%3A//webscraping.com. Then the source website can not block you and does not even know you are crawling their content.