When scraping a website, typically the majority of time is spent waiting for the data to download. So to be efficient I work on multiple scraping projects simultaneously.
This can get overwhelming, so to track progress I built a web interface some time back, internally known as wsui. For large crawls I share a secret link with clients so they can also track progress and sample the scraped results.
The below screenshot shows output for a typical crawl:
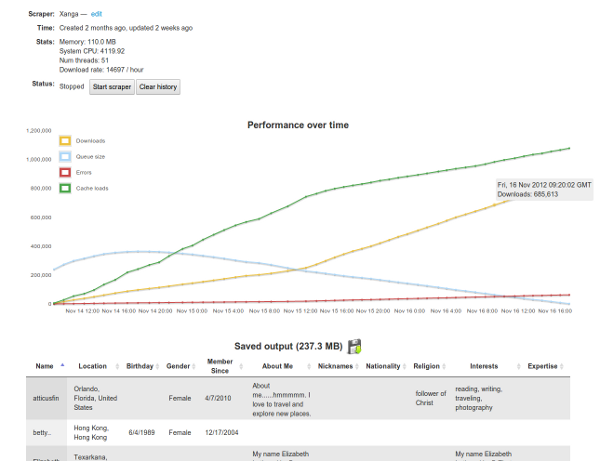
The yellow graph line tracks downloads, the green the number of loads from cache, the blue the number of queued URLs waiting to be downloaded, and the red download errors. There are also statistics for the number of system threads, memory, and CPU used.
This service was built with web2py and is hosted on an ec2 server.